By 2027, the global last-mile delivery market is expected to soar past $200 billion, up from $108.1 billion in 2020. This remarkable growth is fueled by the surge in e-commerce, breakthroughs in delivery technology, and the ever-increasing consumer demand for faster, more efficient delivery services.
With changing customer expectations, supply chain businesses face an urgent need to boost their operational efficiency and scalability without cutting down profit margins. That’s where AI comes in. BCG reports that automation with AI can increase revenues by up to 5% in less than nine months.
AI can revolutionize supply chain operations in numerous ways. Let’s explore the benefits of deploying machine learning algorithms in logistics and their practical applications.
AI and Machine Learning in Logistics: Use Cases with Examples
Practical Applications of AI in the Logistics Industry:
Predictive Analytics: AI predicts demand with remarkable accuracy. For instance, by analyzing historical sales data and current market trends, AI systems can ensure warehouses are stocked with high-demand items before peak shopping seasons. This proactive approach eliminates delays caused by last-minute planning, resulting in quicker delivery times and improved customer satisfaction.
Route Optimization: AI algorithms optimize delivery routes by analyzing real-time traffic data, weather conditions, and other variables. For example, UPS uses AI to predict traffic congestion and reroute trucks accordingly, ensuring timely deliveries even during peak hours. By considering factors like road closures and weather forecasts, AI helps drivers avoid delays and choose the fastest, most efficient paths to their destinations.
Automated Sorting and Processing: AI-powered systems, like those used by Amazon and FedEx, streamline warehouse operations by automating package sorting and order processing. For example, Amazon’s Kiva robots swiftly navigate warehouse floors to pick and sort items, drastically reducing the time it takes to fulfill orders. Similarly, FedEx employs AI-driven sorting machines that process thousands of packages per hour, ensuring faster and more accurate deliveries.
Dynamic Scheduling: AI schedules deliveries and pickups using real-time data to dispatch shipments at optimal times. For instance, DHL uses AI to adjust delivery schedules based on current traffic conditions and customer availability, ensuring timely arrivals.
Inventory Management: AI enhances inventory management by accurately predicting stock levels and ensuring products are available when needed. For example, Walmart uses AI to forecast demand and automatically reorder popular items before they run out, reducing restocking delays. Similarly, Zara leverages AI to monitor inventory in real-time, adjusting stock levels based on sales trends and seasonal demand to keep shelves well-stocked and minimize waiting times for customers.
Monitor Fleet Health With Predictive Analysis: AI predicts when delivery vehicles need maintenance, preventing breakdowns and ensuring timely shipments. For instance, DHL uses AI-powered predictive maintenance to monitor the health of their vehicles, resulting in a 10% reduction in maintenance costs and a 15% reduction in vehicle downtime.
Enhanced Communication: AI chatbots and automated customer service systems provide real-time updates, streamlining customer interactions. For example, Domino’s Pizza uses AI-powered chatbots to instantly answer customer inquiries about order status and delivery times, reducing the need for manual tracking.
Intelligent Packaging Solutions and Material Optimization: AI-driven intelligent packaging solutions and material optimization reduce costs and ensure product integrity. For instance, Nestlé leverages AI to develop smart packaging that monitors product conditions during transit. Smart packaging solutions use sensors to track temperature, humidity, and other factors, reducing the need for additional protective materials and ensuring products remain safe with less packaging.
Data Preparation To Ensure Accurate and Reliable Machine Learning Models
Step 1: Data Collection
Data collection is a critical step in preparing accurate and reliable machine learning models. It involves the systematic gathering of data from diverse sources to create a robust dataset. Here’s an expanded view of the process:
Identifying Data Sources
Internal Data Sources: Collect data from within the organization, such as historical records, transactional databases, CRM systems, and enterprise resource planning (ERP) systems. For example, Amazon collects vast amounts of data from customer interactions, purchase history, and browsing behavior to optimize inventory management, personalize recommendations, and enhance the overall customer experience.
- Historical Records: Collecting historical data provides a foundation for understanding trends and patterns. For example, in supply chain management, this might include past sales data, inventory levels, and production records. This data helps in building models that can predict future demand and optimize inventory levels.
- Transactional Data: Walmart collects and analyzes billions of transactions each week to manage inventory and improve customer service. Gathering transactional data such as sales transactions, purchase orders, and shipping records is essential to analyze current performance and identify areas for improvement.
- Sensor Data: In modern supply chains, IoT devices and sensors play a crucial role. These sensors collect real-time data on various parameters such as temperature, humidity, and location. Companies like Maersk use sensor data to monitor the conditions of refrigerated containers, ensuring the quality of perishable goods during transit.
- Enterprise Resource Planning (ERP) Systems: Data from ERP systems is invaluable as it integrates various business processes. This includes data from finance, HR, manufacturing, and supply chain. For example, SAP’s ERP solutions enable companies to collect and analyze data across different departments, providing a comprehensive view of business operations.
External Data Sources: Data from suppliers, partners, and third-party logistics providers can enrich the dataset. This might include delivery schedules, supplier performance metrics, and market reports. Collaborating with partners to share data ensures that all parties have a comprehensive view of the supply chain, leading to better coordination and efficiency.
- Web and Social Media Data: Collecting data from web sources and social media platforms can provide insights into customer sentiment and market trends. For example, analyzing tweets or reviews can help businesses understand consumer preferences and adjust their supply strategies accordingly
- Public Datasets: Utilizing publicly available datasets can enhance the data collection process. These datasets can include demographic information, economic indicators, and weather data.
Defining Data Requirements
The process of defining data requirements ensures that the data collected is relevant, comprehensive, and high quality, enabling accurate and reliable model predictions. The key steps in defining data requirements are:

Looking to implement AI in your supply chain?
Step 2: Data Cleaning
Data cleaning involves removing duplicates, handling missing values, and correcting inconsistencies to ensure the dataset’s integrity and reliability.
Removing Duplicates
For instance, in a customer database, duplicate entries for the same customer can skew analysis and result in inflated metrics for customer count and purchasing frequency. To address this, algorithms are used to identify and merge duplicate records based on key identifiers like email addresses or customer IDs.
Handling Missing Values
In a dataset of patient records, missing entries for blood pressure readings can be imputed using the average blood pressure values of patients with similar profiles (age, weight, medical history). Likewise, there are three ways to handle missing data:
- Imputation: Replace missing values with the mean, median, or mode of the column. This method works well for numerical data where the missing values are randomly distributed.
- Deletion: Remove rows or columns with missing values, which is suitable when the missing data is minimal.
- Prediction: Use algorithms to predict missing values based on other available data.
Correcting Inconsistencies
Inconsistent data can arise from different data entry formats, errors, or merging datasets from various sources. To clean inconsistent data, begin with identifying common inconsistencies. Data visualization tools such as Informatica can detect patterns and anomalies in your data.
The next step is to apply methods like deduplication, imputation, and standardization, as discussed above. Use programming languages (e.g., Python, R) and tools (e.g., Excel, data cleaning software) for automation and efficiency. Validate the data to ensure accuracy. This can involve cross-referencing with reliable sources or running test analyses to check for expected results. Keep a detailed record of the steps taken to clean the data to track changes, aid future analysis, maintain transparency, streamline workflows, and facilitate troubleshooting.
Step 3: Data Transformation
Converting your data into a standard format to enhance its quality and usability is termed data transformation. Two key techniques in data transformation are normalizing and scaling data to prepare it for analysis.
Normalizing Data
Data normalization adjusts the values of numerical data to a common scale without distorting differences in the ranges of values. This process is especially important when features have different units or scales. Normalizing data ensures that no single feature dominates the analysis due to its scale.
Scaling Data
Scaling adjusts data to fit within a smaller, specified range, which is essential for optimizing algorithms sensitive to data magnitude. For example, in AI/ML computational models like neural networks, the algorithm performs better when all input features are on a similar scale.
By scaling all features to a similar range, the model treats each feature with equal importance, improving its predictive accuracy. Scaling thus standardizes the data, making machine learning algorithms more stable and efficient.
4. Feature Engineering
Feature engineering involves selecting and creating relevant features to enhance a model’s performance.
Feature selection involves identifying the most impactful variables from the dataset. This process reduces dimensionality, improves model interpretability, and prevents overfitting.
For example, in a dataset predicting house prices, relevant features include the number of bedrooms, square footage, and location. AI algorithms can efficiently identify and prioritize relevant features while irrelevant features like the homeowner’s names are excluded to streamline the model and enhance performance, allowing AI to focus on the most impactful variables.
Methods for Feature Creation:
Polynomial Features: Create interactions between features by generating polynomial terms. Polynomial feature creation transforms the original features into higher-dimensional features by including polynomial terms (e.g., squares, cubes) and interaction terms (e.g., product of two features). This transformation allows models to capture non-linear relationships between variables without explicitly using non-linear models.
Date and Time Features: Extracting date and time features involves breaking down datetime data into individual components like year, month, day, and hour. This process helps in uncovering temporal patterns and trends within the data. For instance, in a retail dataset, extracting the month and day from sales data can reveal seasonal shopping trends or specific days with higher sales.
Similarly, breaking down timestamps into hours can help identify peak activity periods in web traffic data. By converting datetime data into these granular features, machine learning models can more effectively learn and predict patterns related to time. This approach enhances the model’s ability to make accurate predictions based on time-related factors.
Aggregations: Aggregations calculate summary statistics over groups of data to identify patterns and insights. For example, you can compute the mean, median, or sum of sales for each customer to determine average spending habits. Aggregated data helps understand central tendencies and the overall behavior of data within specific groups.
For instance, a business might calculate total sales per region to identify high-performing areas. Aggregating data by time periods, like weekly or monthly sales, reveals trends and seasonal patterns. These metrics provide a simplified view of complex data, making analysis and decision-making more straightforward.
Explore AI solutions that optimize your logistics and boost your revenue.
How To Choose The Right Machine Learning Algorithms For Your Supply Chain
Regression models might be appropriate for forecasting continuous variables like demand and inventory levels, while decision trees could be ideal for classification tasks such as determining shipment urgency. Neural networks, on the other hand, are suited for complex pattern recognition tasks, such as optimizing warehouse operations and predicting delivery times.
Choosing the right machine learning models ensures that the predictions and insights generated are accurate, actionable, and relevant to improving supply chain efficiency. Each method offers unique advantages for solving challenges within the supply chain. Let’s explore the different types of ML models and their potential use cases.
Supervised Learning
Regression Models
They’re useful for predicting continuous outcomes such as demand forecasting, inventory levels, and transportation costs. For example, linear regression can predict future sales based on historical data and market trends.
Decision Trees
They help in making decisions by splitting data into branches based on feature values. This is useful for classification tasks such as categorizing shipment urgency or determining the best shipping method based on package characteristics.
When a new shipment order is received, the AI/ML system uses the decision tree to evaluate the shipment’s features and assign an urgency level. This automation helps the company prioritize shipments, ensuring that high-urgency deliveries are handled promptly while optimizing resources for lower-urgency shipments.
By using decision trees, the company can streamline its operations, reduce manual classification errors, and improve overall delivery performance. This method provides a clear and interpretable way to make decisions based on multiple features, making it a valuable tool in supply chain management.
Neural Networks
As discussed earlier, neural networks are effective for complex pattern recognition tasks, such as predicting delivery times, optimizing warehouse operations, and identifying anomalies in supply chain data. Deep learning models can handle large datasets and capture intricate relationships between variables, leading to actionable insights and operational efficiency.
Unsupervised Learning
Unsupervised learning is a type of machine learning where the model is trained on unlabeled data without explicit instructions on what to predict. The model identifies patterns and relationships within the data by itself. Let’s look at a few examples relevant to the logistics and supply chain industry.
Clustering Models
They group similar data points, which can be used for segmenting products, customers, or shipments. Clustering can identify patterns in customer orders to optimize delivery schedules or group products with similar storage requirements.
For example, retail companies use clustering algorithms to segment customers based on purchasing habits, enabling targeted marketing campaigns.
Association Rules
They identify relationships between variables in large datasets. This type of machine learning model is often used in market basket analysis. For example, suppose data shows that customers often buy bread and butter together. In that case, a retailer can ensure these items are stocked near each other to boost sales and improve customer convenience. This insight helps in optimizing inventory management by ensuring that products with strong associations are always available, reducing the risk of stockouts and increasing sales efficiency.
Reinforcement Learning
Reinforcement learning (RL) excels in scenarios with numerous interacting components, such as coordinating multiple warehouses, optimizing supply chain networks, and managing automated storage and retrieval systems.
For example, RL can dynamically route deliveries between warehouses based on current inventory and demand, adapting to changes in real time. In another case, it can optimize supply chain networks by continuously improving routing strategies to reduce costs and delivery times. RL adapts to changing conditions, enhancing operational efficiency and decision-making over time.
Deploying Machine Learning Models in Logistics and Supply Chains
How to embed ML models into current logistics and supply chain management systems:
Understand The Architecture
Broadly, this involves two steps:
- Logistics System Mapping: Document all hardware, software, databases, and network configurations. This includes ERP (Enterprise Resource Planning), WMS (Warehouse Management Systems), and TMS (Transportation Management Systems).
- Identify Integration Points: Determine where the ML model fits within the existing architecture. For instance, if the model predicts demand, identify where this data will be injected into the ERP system for inventory management.
Analyze Data Flow
As discussed in the Data Preparation section, analyzing data flow involves understanding how data is collected, processed, and stored within your logistics system. This step ensures that the ML model has access to the right data in the required format.
Analyze Operational Workflows
This step involves determining how tasks are performed and where ML models can add value, as well as ensuring that ML integration aligns with business processes and enhances operational efficiency.
- Document current logistics workflows in detail. This includes order processing, inventory management, shipping, and delivery.
- Identify inefficiencies or bottlenecks in the current workflows that ML models can address. For example, look for delays in order processing or inaccuracies in inventory management.
- Work with process owners and stakeholders to understand their needs and ensure that the ML model addresses the problems they’re trying to solve.
The above strategic approach and integration enhance operational efficiency, optimize inventory management, improve supply chain performance, and bring down logistics expenses by 20%.
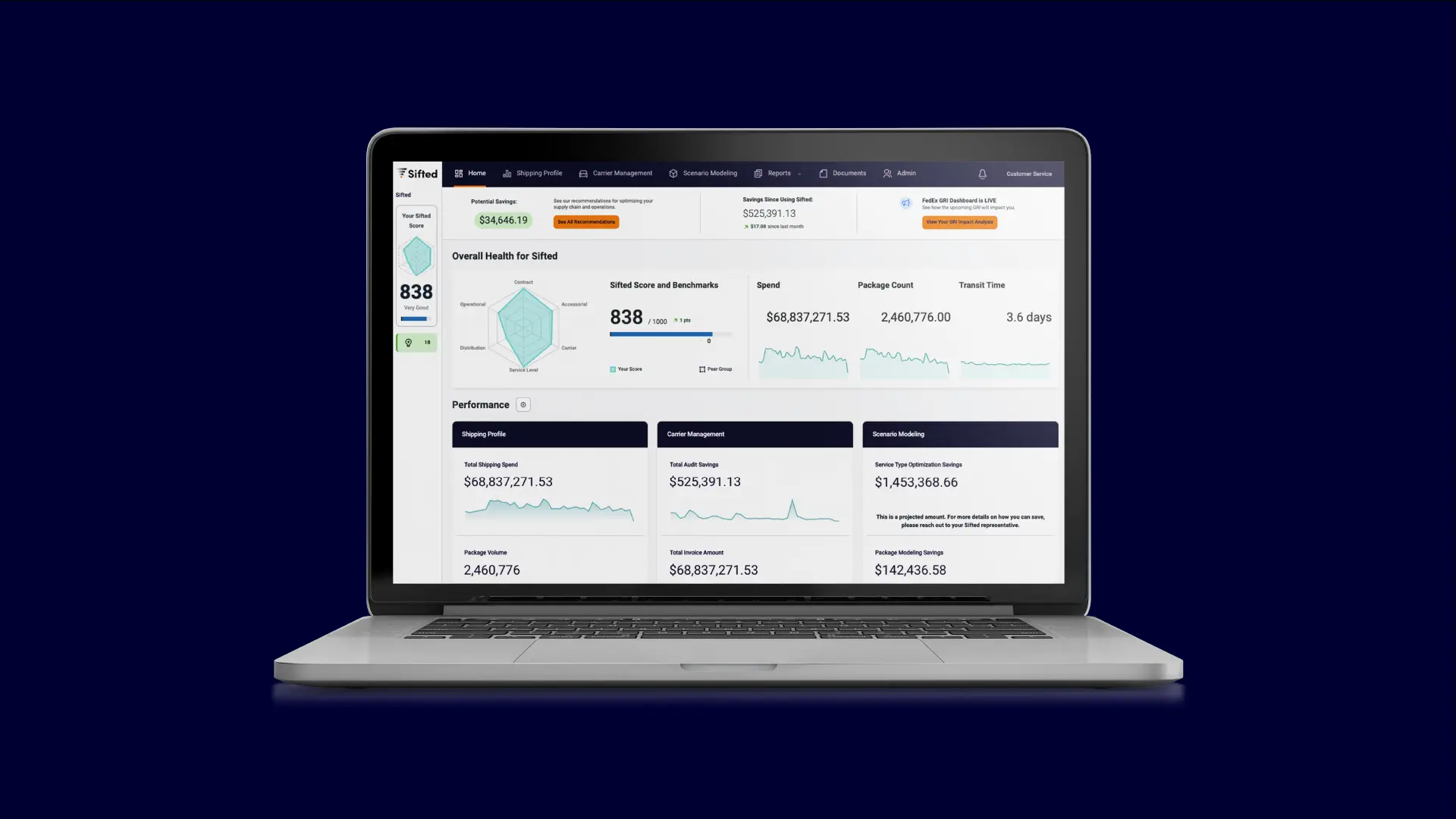
Sifted Logistics Intelligence
Ready to implement logistics intelligence in your supply chain? Get in touch with us now.